最近我沉迷于结合 StrandsAgents 与 StrandsAgents Tools 来开发各类智能体(Agent)。
本次将为大家介绍一种方法:通过结合 StrandsAgents 与 Claude 4 ,无需构建多智能体(Multi-Agent),即可生成媲美DeepResearch的调查报告
1. 引言
自 2025 年初 OpenAI 发布DeepResearch功能以来,AI 领域对高级信息调查与分析功能的关注度迅速提升。
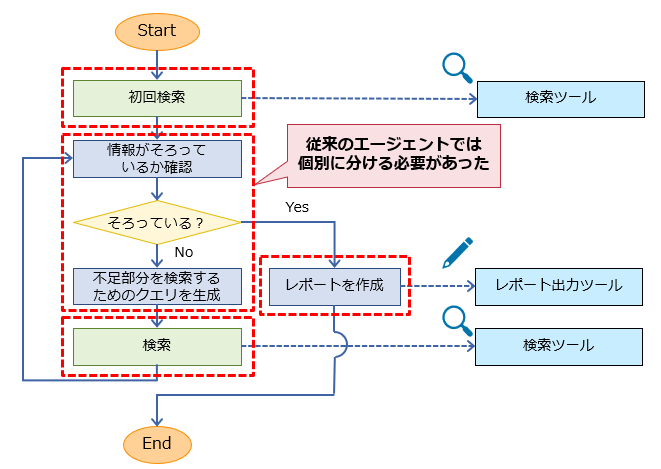
以往,要实现复杂调查任务的自动化,需构建多智能体架构或设计复杂的工作流程。
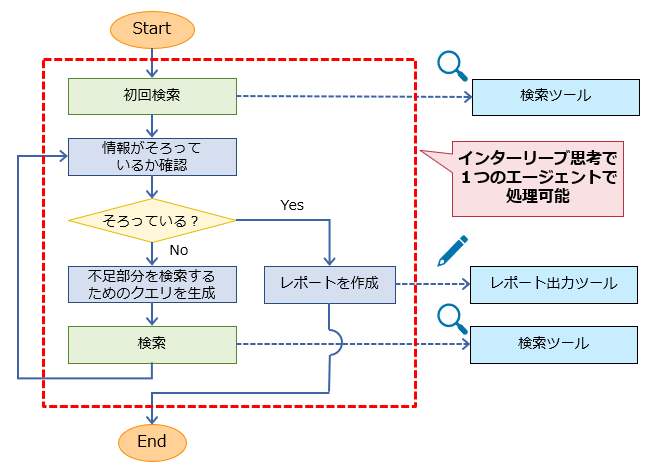
但本次我们发现,通过结合 StrandsAgents 与 Claude 的交织思考功能,仅用单智能体即可实现媲美 DeepResearch 的功能。
本文将详细讲解这一革新性方法,从实现过程到执行结果逐一说明。
1.1 关于DeepResearch
DeepResearch 是一项利用 AI 实现的高级信息收集、分析与报告生成功能。
作为可在短时间内自动化处理复杂调查任务的下一代研究工具,它备受关注。
该功能能够在仅 5 至 30 分钟内完成人类原本需要数小时甚至数天才能完成的信息收集与分析工作。
以 OpenAI 的 DeepResearch 为代表,Google(Gemini)、Anthropic(Claude)、Perplexity AI、xAI(Grok)等主流 AI 企业纷纷推出类似功能,该领域的竞争日趋激烈。
1.2 什么是 StrandsAgents
StrandsAgents 是 AWS 开发的开源 AI 智能体构建框架,具有以下特点:
| 特点 | 概述 |
|---|---|
| 简洁设计 | 基于 Python,提供直观的 API |
| 模型驱动型方法 | 支持多个大型语言模型(LLM)提供商 |
| 工具丰富 | 提供 20 余种预置工具 |
| 支持 MCP 协议 | 可与模型上下文协议(MCP)服务器集成 |
什么是交织思考(Interleaved Thinking)
交织思考(Interleaved Thinking)是 Claude 4 模型引入的革新性功能。
它是对传统扩展思考(Extended Thinking)的升级,能够在工具使用过程中插入思考流程。
具体可实现以下操作:
- 工具结果分析:接收工具调用结果后,对内容进行思考
- 动态策略调整:根据实际情况修正初始计划
- 阶段性推理:在多次工具调用之间插入推理步骤
通过Interleaved Thinking,可实现更接近人类的灵活思考流程,而非简单的线性处理。
此外,Interleaved Thinking仅支持以下模型:
- Claude Opus 4
- Claude Sonnet 4
- Claude Sonnet 3.7
■ 传统 DeepResearch 智能体架构
■ 采用交织思考的 DeepResearch 智能体架构
2. 实现
2.1 智能体(Agent)
本次实现以 DeepResearch 类为核心构建,核心代码如下:
import asyncio
import os
from textwrap import dedent
from mcp import StdioServerParameters, stdio_client
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands.tools.mcp import MCPClient
TAVILY_API_KEY = os.getenv('TAVILY_API_KEY')
websearch = MCPClient(
lambda: stdio_client(
StdioServerParameters(
command='npx',
args=['-y', 'tavily-mcp@latest'],
env={'TAVILY_API_KEY': TAVILY_API_KEY},
)
)
)
class DeepResearch:
PROMPT = dedent("""\
请针对用户提出的待调查主题,生成一份相当于3页PDF篇幅的详细且全面的报告。
报告请采用Markdown格式排版。
报告必须使用中文撰写。
报告内容需通过网络搜索收集。
请仔细斟酌收集到的内容,若判断需要进一步深入调查,可重新编写搜索关键词并继续进行网络搜索。
重要的是要收集用户指定主题的全面信息。
请在脚注中注明参考网站,脚注格式为`[脚注编号][标题](URL)`。
""")
def __init__(self, tools):
model = BedrockModel(
model='us.anthropic.claude-sonnet-4-20250514-v1:0',
streaming=True,
additional_request_fields={
'thinking': {'type': 'enabled', 'budget_tokens': 4000},
'anthropic_beta': ['interleaved-thinking-2025-05-14'],
},
)
self.agent = Agent(
model=model,
system_prompt=self.PROMPT,
tools=tools,
)
async def stream(self, prompt):
async for event in self.agent.stream_async(prompt):
if text := event.get('event', {}).get('contentBlockDelta', {}).get('delta', {}).get('text', ''):
yield text
for content in event.get('message', {}).get('content', []):
if isinstance(content, dict) and (tool_use := content.get('toolUse', '')):
print(tool_use)
2.2 模型(启用Interleaved Thinking功能)
需进行以下设置以启用 Claude 4 的Interleaved Thinking功能:
model = BedrockModel(
model='us.anthropic.claude-sonnet-4-20250514-v1:0',
streaming=True,
additional_request_fields={
'thinking': {'type': 'enabled', 'budget_tokens': 4000},
'anthropic_beta': ['interleaved-thinking-2025-05-14'],
},
)
要点
| 设置 | 作用 |
|---|---|
| thinking | 启用扩展思考,设置思考令牌(Token)预算 |
| anthropic_beta | 启用Interleaved Thinking功能的 Beta 版请求头 |
| streaming | 启用结果实时输出功能 |
通过上述设置,智能体能够在工具使用间隙插入思考流程,动态修正调查策略。
2.3 工具(Tavily MCP)
Tavily MCP 服务器提供专为 AI 设计的高级搜索与数据提取功能。
它通过模型上下文协议(MCP)与 StrandsAgents 集成。
2.3.1 Tavily MCP 服务器的特点
| 特点 | 概述 |
|---|---|
| AI 优化搜索 | 提供针对 LLM 优化的搜索结果 |
| 实时信息 | 可访问最新的网络信息 |
| 多样搜索功能 | 支持通用搜索、新闻搜索、指定域名搜索 |
| 结构化数据提取 | 从网页中 AI 驱动提取内容 |
2.3.2 MCP 集成实现
websearch = MCPClient(
lambda: stdio_client(
StdioServerParameters(
command='npx',
args=['-y', 'tavily-mcp@latest'],
env={'TAVILY_API_KEY': TAVILY_API_KEY},
)
)
)
通过该实现,智能体可访问以下工具:
- tavily-search:通用网络搜索
- tavily-extract:特定 URL 内容提取
- tavily-crawl:网站结构化爬取
- tavily-map:生成网站地图
3. 执行
作为实际执行示例,我们以 “关于 StrandsAgents” 为查询词进行了测试。
3.1 思考过程
为生成关于 “StrandsAgents” 的详细报告,需进行网络搜索。首先从基础信息开始调查。
Tool #1: tavily-search{‘toolUseId’: ‘tooluse_nlRia3AiSxKtTqIcUIW5tA’, ‘name’: ‘tavily-search’, ‘input’: {‘query’: ‘StrandsAgents 是什么 概述 特点 ‘, ‘search_depth’: ‘advanced’, ‘max_results’: 10}}
首先,为获取更多关于 StrandsAgents 的详细信息,我们查看官方文档内容。
Tool #2: tavily-extract{‘toolUseId’: ‘tooluse_FgM2FQAIRfqQIq-BWzAAwA’, ‘name’: ‘tavily-extract’, ‘input’: {‘urls’: [‘https://strandsagents.com/latest/‘, ‘extract_depth’: ‘advanced’}}
为收集更详细的信息,我们进一步调查一些具体的使用案例和实现示例。
Tool #3: tavily-search{‘toolUseId’: ‘tooluse_BYQQst_8RTKNMl29XzB8zA’, ‘name’: ‘tavily-search’, ‘input’: {‘query’: ‘Strands Agents 实现示例 代码样本 使用案例 ‘, ‘search_depth’: ‘advanced’}}
我们更详细地调查 StrandsAgents 的实现案例和代码结构,查看官方文档的代码样本。
Tool #4: tavily-extract{‘toolUseId’: ‘tooluse__1NIfbQpT0GQN2_k2-a2hg’, ‘name’: ‘tavily-extract’, ‘input’: {‘urls’: [‘https://strandsagents.com/latest/user-guide/quickstart/‘], ‘extract_depth’: ‘advanced’}}
为更深入理解多智能体系统,我们查看相关文档。
Tool #5: tavily-extract{‘toolUseId’: ‘tooluse_J8RqHAfaSuekfKVMyWZ13A’, ‘name’: ‘tavily-extract’, ‘input’: {‘urls’: [‘https://strandsagents.com/latest/user-guide/concepts/multi-agent/agents-as-tools/‘], ‘extract_depth’: ‘advanced’}}
接下来,作为 Strands Agents 的实用示例,我们查看检索增强生成(RAG)的实现案例。
Tool #6: tavily-search{‘toolUseId’: ‘tooluse_E2gPYoibQb2LECRZ2iXf-Q’, ‘name’: ‘tavily-search’, ‘input’: {‘search_depth’: ‘advanced’, ‘query’: ‘Strands Agents RAG 实现 知识库 retrieve 工具 示例 ‘}}
我们查看具体的样本代码。为理解使用知识库的 RAG 实现细节,调查相关文档。
Tool #7: tavily-extract{‘toolUseId’: ‘tooluse_ExrhAWzjT6ykET0fSdrvvA’, ‘name’: ‘tavily-extract’, ‘input’: {‘urls’: [‘https://strandsagents.com/latest/examples/python/knowledge_base_agent/‘], ‘extract_depth’: ‘advanced’}}
接下来,我们也调查使用 Strands Agents 时的问题和限制。
Tool #8: tavily-search{‘toolUseId’: ‘tooluse_slS6HdbjTpC4hraWyh25Jg’, ‘name’: ‘tavily-search’, ‘input’: {‘search_depth’: ‘advanced’, ‘query’: ‘Strands Agents 限制 问题 缺点 安全性 ‘}}
我们还调查 Strands Agents 的实用案例和企业导入案例。
Tool #9: tavily-search{‘toolUseId’: ‘tooluse_DbBWLVxnRhu4nXtHPP8E_Q’, ‘name’: ‘tavily-search’, ‘input’: {‘search_depth’: ‘advanced’, ‘query’: ‘Strands Agents 案例 企业导入 使用案例 Amazon Q Developer AWS Glue’}}
最后,我们收集关于 Strands Agents 的未来前景和发展展望的信息。
Tool #10: tavily-search{‘toolUseId’: ‘tooluse_D_GJqij3Q0eLbXbHXHI7ww’, ‘name’: ‘tavily-search’, ‘input’: {‘search_depth’: ‘advanced’, ‘query’: ‘Strands Agents 未来前景 展望 路线图 功能扩展 ‘}}
整理所有收集到的信息,生成关于 StrandsAgents 的全面报告。
从上述思考与工具使用记录可以看出,通过启用交织思考功能,实现了基于搜索结果扩展查询词、进一步搜索详细信息的深度研究级操作,具体流程如下:
- 初次搜索:通过 “StrandsAgents 是什么 概述 特点” 获取基础信息
- 判断与追加搜索:根据结果添加 “RAG”“使用案例” 等关键词
- 再搜索:深入挖掘专业领域及最新案例
- 生成 Markdown 报告:附带脚注输出
执行结果
最终生成的报告包含以下全面内容:
- 概述:基础信息、特点
- 主要功能:主要功能、工具、多智能体
- 实现:智能体、自定义工具、RAG 实现
- 应用:应用案例、最佳实践、与其他框架的对比
- 负责任的 AI:防护措施、注意事项
4. 要点
对于像 DeepResearch 这类以往需通过多智能体架构实现的功能,采用交织思考的单智能体构建方式具有以下优势。
4.1 无需复杂实现
传统多智能体架构存在以下复杂性:
- 智能体间通信协议的设计
- 任务分配与工作流程管理
- 状态管理与同步处理
- 错误处理与恢复机制
而通过利用交织思考,在单智能体内(约 70 行代码)即可实现:
- 思考与搜索的循环:自然的推理流程
- 动态策略调整:灵活修正初始计划
- 信息递归获取:按需进行追加调查
4.2 减少信息缺失(Hallucination)
多智能体架构的问题
- 信息传递劣化:智能体间的上下文丢失
- 责任分散:难以定位错误信息来源
- 一致性维护:多智能体间的信息一致性保障
单智能体 + 交织思考的优势
- 上下文延续:所有信息在单一会话内管理
- 来源一致性:搜索结果与推理流程直接关联
- 质量管控:单一模型实现一致的质量标准
总结
本文详细讲解了通过 StrandsAgents + Claude (Interleaved Thinking)实现单智能体深度研究(DeepResearch)的方法。
主要成果
- 架构简化:无需复杂的多智能体架构
- 质量提升:大幅减少信息缺失
- 开发效率提高:实现、调试、运维全阶段效率提升
- 实用性验证:在实际企业调查中生成高质量报告
未来展望
随着Interleaved Thinking技术的发展,有望实现更高级的 AI 智能体:
- 自主学习:调查流程本身的学习与优化
- 专业化:领域专用型高精度智能体
- 协作:多个专用智能体的高效协同
StrandsAgents + Claude( Interleaved Thinking)是 AI 智能体技术实用化进程中的重要里程碑技术。
这种简洁而强大的方法,有望成为未来 AI 应用开发的新标杆。