
最近,我养成了一个习惯:想要查询什么内容时,不会再依赖普通的搜索引擎,而是向生成式 AI 提问。生成式 AI 能让我清晰易懂地获取想要的信息,其近年来的发展速度实在令人惊叹。
不过,即便使用生成式 AI,若要完成的不是简单搜索,而是多方查找相关信息,依然相当耗时。这时,“深度研究(DeepResearch)” 就显得格外实用了 —— 它能针对用户的问题进行更广泛、更深入的思考后再给出答案。目前已有多款生成式 AI 服务推出了这一功能,本次我将介绍如何使用 Dify 实现 “DeepResearch” 功能。
1. 概述
什么是 DeepResearch
DeepResearch 并非局限于简单的关键词搜索,而是基于搜索结果逐步深入挖掘下一步所需信息,从而实现自动化、全面性调查的流程。
它是 OpenAI 于 2025 年 2 月发布的、集成于 ChatGPT 的高级 AI 智能体,旨在高效自动化处理复杂的调查任务。该功能能在数十分钟内完成人类需耗费数小时才能达成的工作 —— 从互联网上的海量信息源中收集相关数据、进行分析整合并生成全面报告,因此备受关注。
什么是 Dify
Dify 是一个无需代码即可创建生成式 AI 应用与工作流的开源平台。
通过图形用户界面(GUI),用户能直观地构建利用生成式 AI(LLM)的应用、智能体及工作流。此外,该平台支持灵活选择和组合 ChatGPT、Claude、Bedrock 等多个模型,让开发者能轻松开展基于 LLM 的应用开发。
2. 用 Dify 工作流实现 DeepResearch
Dify 提供了 DeepResearch 的模板。关于构建方法,请参考 Dify 官方博客的文章 DeepResearch: Building a Research Automation App with Dify。
这款 DeepResearch 模板似乎是由日本人岸田崇史先生创作,并被采纳为 Dify 官方模板的。
工作流说明
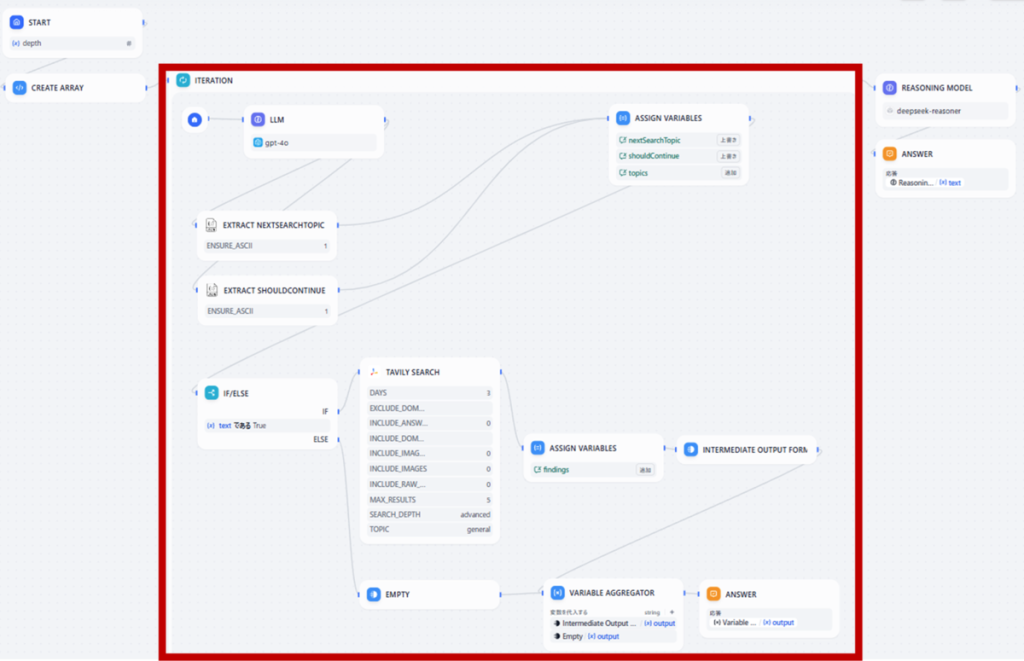
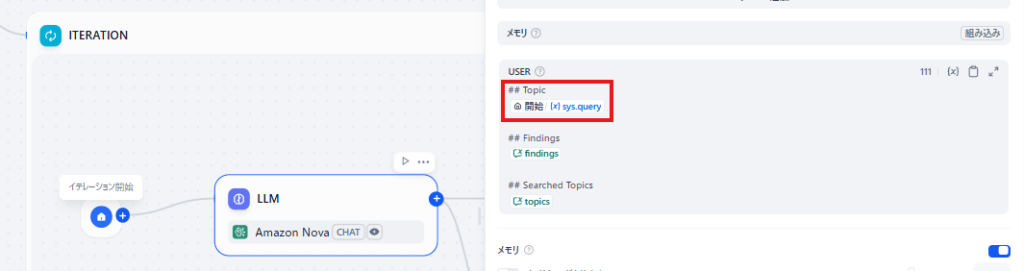
上图即为加载了模板后的工作流。
重现 DeepResearch 功能的核心部分,是红框标出的迭代块(Iteration Block)。以用户输入为基础,以 LLM 节点初始设定的搜索关键词为起点,AI 会接连生成新的搜索主题,并自动执行连续调查。
借助这一机制,原本手动操作需耗费大量时间的多维度、深层次研究得以实现自动化。该迭代过程会重复进行,直至达到 “开始(START)” 节点指定的次数,或 LLM 节点判定无需继续调查为止。
本文中对模板的修改主要是调整了 LLM 块的 AI 模型,具体如下:
| 块名称 | 说明 | 所使用的 LLM 模型 |
|---|---|---|
| LLM | 生成搜索主题 | Nova Pro |
| Reasoning Model | 对主题进行全面分析 | Claude 3.7 Sonnet |
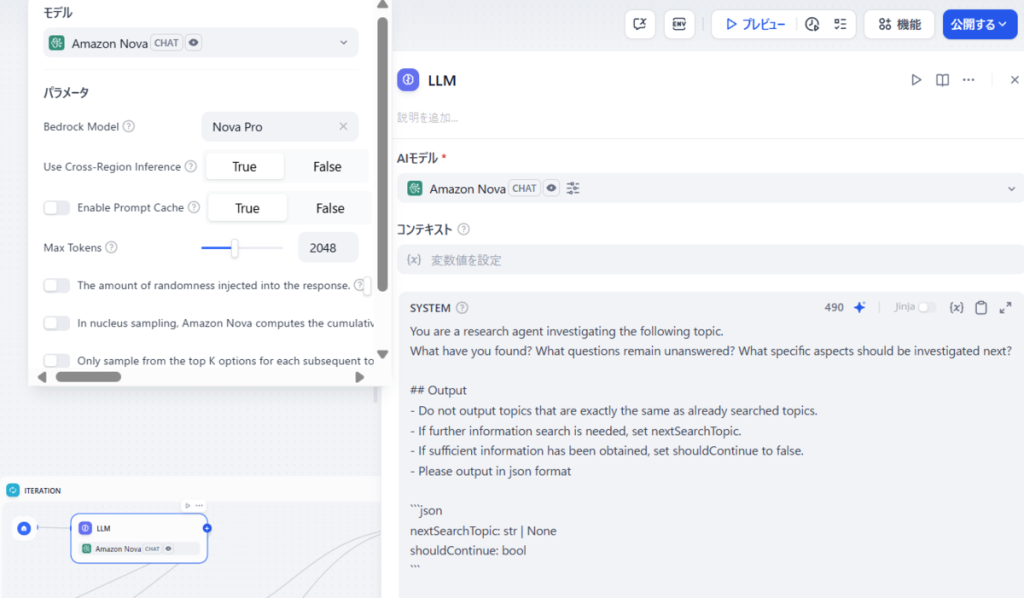
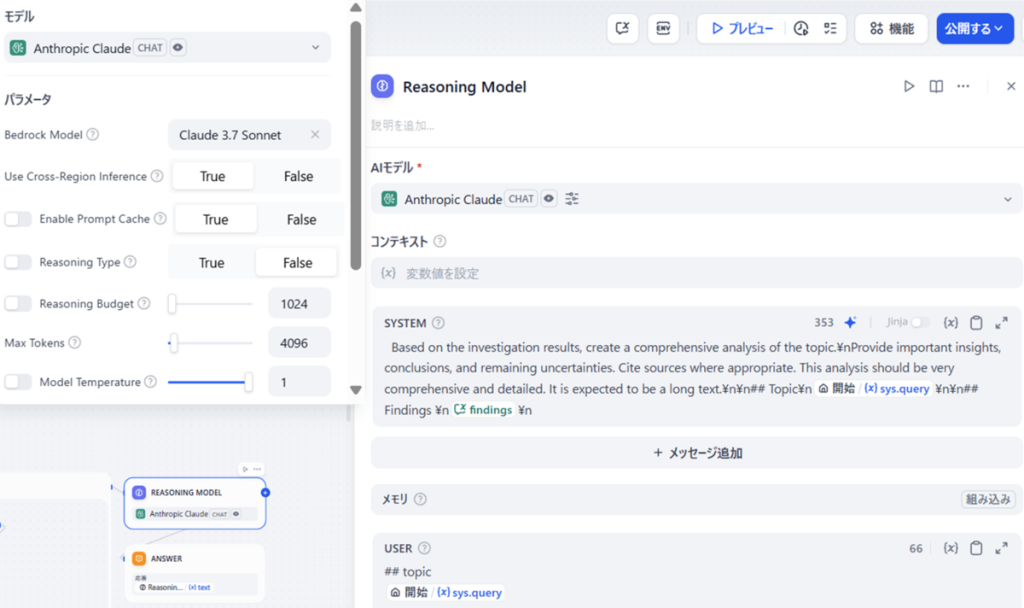
※假设 Dify 已实现与 Bedrock 的联动
此外,由于出现过搜索思考过程显示为英语的情况,我在系统提示词中补充了 “思考过程全程以中文输出” 的要求。
修正系统提示词,确保输出过程也以中文显示
工作流中迭代块(Iteration Block)的算法说明
1. 工作流的输入
工作流的输入包含以下两项:
① depth:迭代的最大次数(可选)
② sys.query:用户最初输入的 “待调查主题”
迭代块的输入② sys.query
2. 搜索主题的生成方法
搜索主题由 LLM 生成,赋予 LLM 的系统提示词如下。简言之,就是从已搜索结果中找出尚未明确的信息点,生成与过往搜索主题不重复的新主题进行再次搜索。
You are a research agent investigating the following topic.
What have you found? What questions remain unanswered? What specific aspects should be investigated next?
## Output
- Do not output topics that are exactly the same as already searched topics.
- If further information search is needed, set nextSearchTopic.
- If sufficient information has been obtained, set shouldContinue to false.
- Please output in json format
- Please output everything, including the search output process, in Japanese.
{
nextSearchTopic: str | None
shouldContinue: bool
}
3. 如何判断是否需要再次搜索
退出迭代的条件有以下两项:
- shouldContinue 设为 False 时
- 迭代次数达到 depth 指定值时
3. 实际运行工作流
接下来,我们在 Dify 上实际运行这个工作流。
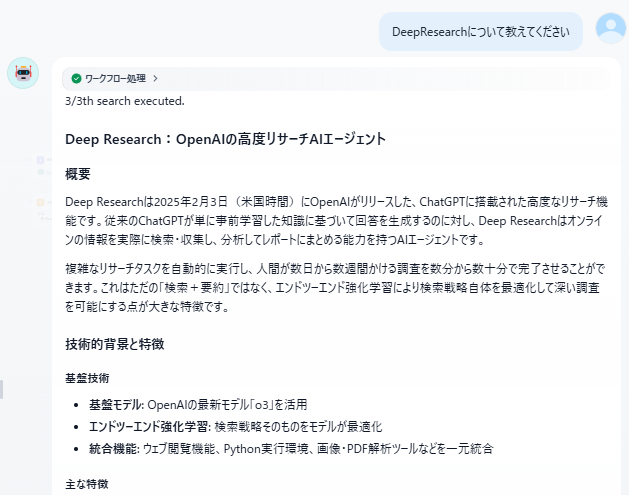
当我针对 DeepResearch 提问后,得到了如下输出结果。它不仅说明了概要,还检索了相关附带信息,给出了明确的答案。
此外,概要说明也参考了多个信息源,可以说生成了一份可信度极高的报告。
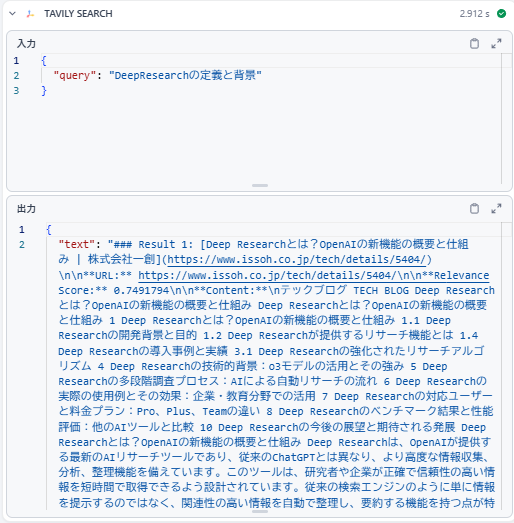
而且,打开 AI 输出的工作流处理记录,还能查看搜索过程的结果。
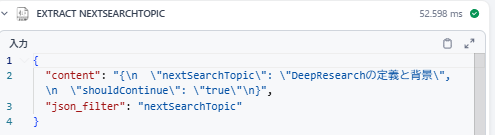
从下图中可以确认:系统会针对输入关键词生成下一个搜索主题(nextSearchTopic);若需要继续搜索,shouldContinue 标记会设为 “true”。
各块的执行时间
| 序号 | 块名称 | 执行时间(秒) |
|---|---|---|
| 1 | Start | 0.080 |
| 2 | 数组创建 | 0.108 |
| 3 | 第 1 次迭代 | 4.563 |
| 4 | 第 2 次迭代 | 4.866 |
| 5 | 第 3 次迭代 | 2.225 |
| 6 | Reasoning Model | 55.904 |
| 7 | 回答 | 0.039 |
| 合计 | – | 67.885 |
4. 总结
本文介绍了使用 Dify 实现 DeepResearch 的方法。
借助 Dify,AI 能连续检索、分析生成的主题,并自动控制调查深度,从而实现 DeepResearch 功能。此外,AWS 的 Bedrock 与 Dify 的联动也十分便捷,支持灵活选择模型。欢迎大家将其引入自己的项目中,亲身体验调查工作的效率提升。