
每天都为 AI 的发展速度所惊叹,不仅是生成式 AI,数据活用的机制也在不断进步。
这次,我想尝试去年 12 月开始支持的 Bedrock 知识库的自定义数据源以及文档直接导入 API!
1. 前言
在检索增强生成(RAG)的应用日益广泛的背景下,保持知识库信息的时效性至关重要。
然而,以下问题经常成为实际应用中的痛点:
- 需对数据源进行整体同步,处理耗时较长
- 难以实时反映最新信息
- 与 Bedrock 知识库不支持的数据源进行联动时手续繁琐
自定义数据源与直接导入 API 能够有效解决上述问题。本文将介绍实际尝试这些功能的相关内容。
2. 自定义数据源 + 直接导入 API 的概述与优势
什么是自定义连接器?
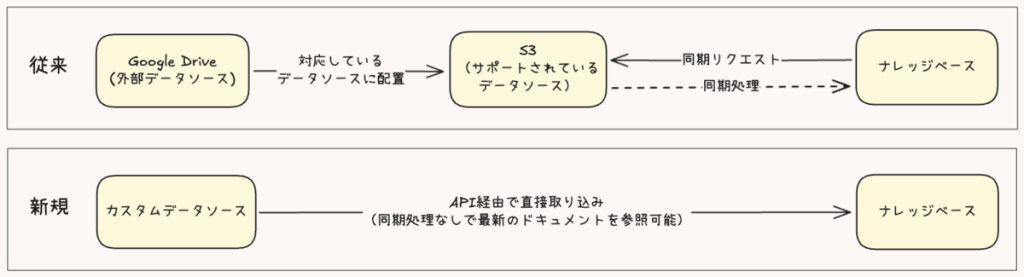
在以往的知识库中,仅能从 S3 等有限的数据源导入文档。
例如,若要从 Google Drive 等未支持的数据源导入文档,需要先将文档复制到 S3 等受支持的数据源中,再进行导入,这种中间处理环节既繁琐又耗时。
这就导致了数据导入延迟、运维工作量增加等问题。
但随着自定义连接器的支持,无需经由 S3 等中间环节,可通过 API 直接从任意外部数据源导入文档!
什么是文档直接导入?
在以往的知识库中,为了能查阅到最新导入的文档,需要执行数据源与知识库之间的数据同步处理。
例如,在处理新闻等更新频繁的数据时,就需要定期执行数据同步处理,十分不便。
而文档直接导入功能的支持,省去了知识库与数据源之间的定期同步处理,确保了文档导入的实时性与效率,能够始终为用户提供最新数据!
| 对比维度 | 以往方式 | 应用自定义数据源 + 直接导入 API 后 |
|---|---|---|
| 数据源适配 | 不支持的数据源需先临时导入 S3 等服务 | 可从任意数据源导入文档 |
| 数据更新机制 | 需与数据源进行同步 | 可直接导入文档,实现近乎实时信息更新 |
3. 实际尝试
文档直接导入功能可通过下表中的组合方式使用。本次将尝试通过自定义数据源,投入采用内联定义的文档(即表中左下区域的组合)。
| 数据源 | 内联定义的文档 | S3 中存储的文档 |
|---|---|---|
| S3 | ❌ | ⭕️ |
| 自定义 | ⭕️ | ⭕️ |
“内联定义的文档” 这一表述可能较难理解,其实是指在 API 的请求体中直接指定文档内容。此外,即便使用自定义数据源,也可无需同步直接导入 S3 中存储的文档。
事前准备(创建知识库)
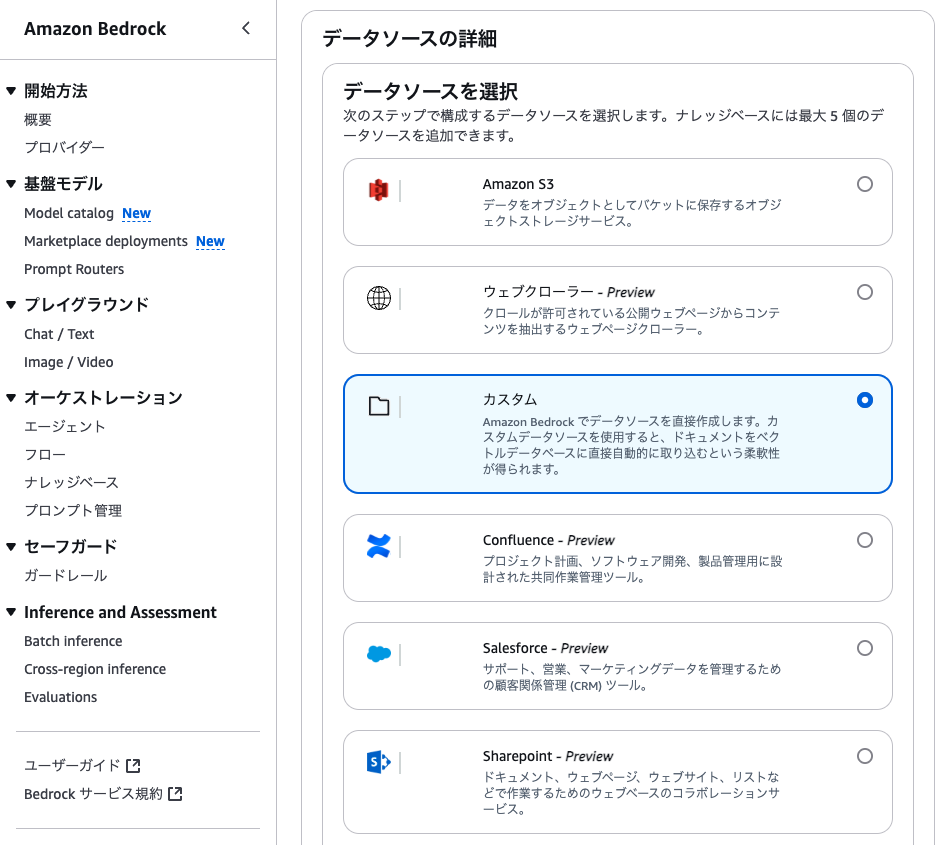
从 AWS 管理控制台进入 Bedrock 服务页面,创建知识库。由于本次需使用自定义数据源,因此在数据源选择页面中选择 “自定义”(Custom)。
从 AWS 管理控制台导入文档
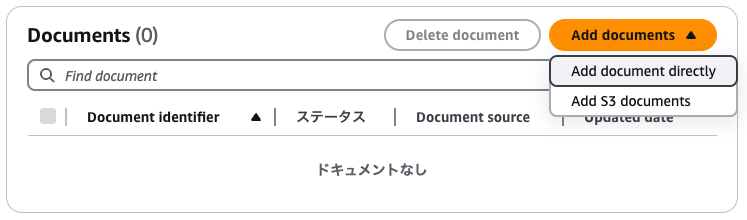
从已创建的知识库进入数据源页面,从 “Add documents”(添加文档)下拉菜单中选择 “Add document directly”(直接添加文档)。
进入待导入文档的设置页面后,尝试以内联方式定义并添加示例文本数据。系统支持指定纯文本或 Base64 编码的字符串,本次输入纯文本 “这是示例数据。”。
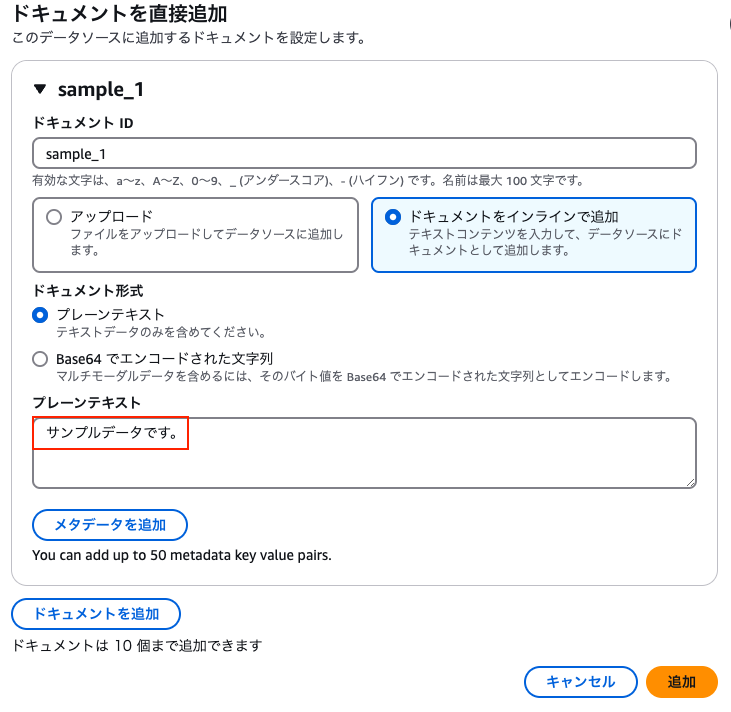
可在知识库的数据源页面确认文档是否已添加。经确认,借助文档直接导入功能,无需与数据源同步即可将文档导入知识库。

从 API 导入文档
通过 AWS 管理控制台导入文档属于手动操作。考虑到实际运营需求,我们也需要确认通过代码调用 API 的实现方法。本文将使用 boto3 库编写 Python 程序进行尝试。
在 boto3 中,导入文档需使用ingest_knowledge_base_documents方法。
import uuid
import boto3
bedrock_client = boto3.client("bedrock-agent")
response = bedrock_client.ingest_knowledge_base_documents(
knowledgeBaseId=<知识库ID>,
dataSourceId=<数据源ID>,
documents=[
{
"content": {
"dataSourceType": "CUSTOM",
"custom": {
"customDocumentIdentifier": {
"id": str(uuid.uuid4()),
},
"sourceType": "IN_LINE",
"inlineContent": {
"type": "TEXT",
"textContent": {
"data": "这是示例数据。",
},
},
},
},
},
],
)
对于 PDF 等类型的文档,可通过修改inlineContent的内容为字节格式进行导入,示例如下:
response = bedrock_client.ingest_knowledge_base_documents(
knowledgeBaseId=<知识库ID>,
dataSourceId=<数据源ID>,
documents=[
{
"content": {
"dataSourceType": "CUSTOM",
"custom": {
"customDocumentIdentifier": {
"id": str(uuid.uuid4()),
},
"sourceType": "IN_LINE",
"inlineContent": { # 修改此属性
"type": "BYTE",
"byteContent": {
"data": "Amazon Bedrock Knowledge Bases是在Amazon Bedrock上构建的、面向检索增强生成(RAG)应用程序的数据连接功能。".encode(),
"mimeType": "application/pdf",
},
},
},
},
},
],
)
为确保万无一失,我们还需确认知识库能否基于导入的文档进行回答。可通过以下代码向知识库提问:
import boto3
bedrock_agent_runtime_client = boto3.client("bedrock-agent-runtime")
response = bedrock_agent_runtime_client.retrieve_and_generate(
input={"text": "请介绍一下Knowledge Bases。"},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": <知识库ID>,
"modelArn": <已启用访问权限的模型ARN>,
},
},
)
print(response["output"]["text"])
# "Amazon Bedrock Knowledge Bases是在Amazon Bedrock上构建的、面向检索增强生成(RAG)应用程序的数据连接功能。"
从结果来看,模型确实基于导入的文档生成了回答。
从数据源获取文档列表
获取数据源中已添加的文档列表需使用list_knowledge_base_documents方法。
响应结果格式如下:
json
{
"documentDetails": [
{
"dataSourceId": <数据源ID>,
"identifier": {
"custom": {
"id": "sample_1"
},
"dataSourceType": "CUSTOM"
},
"knowledgeBaseId": <知识库ID>,
"status": "INDEXED",
"statusReason": "",
"updatedAt": "2025-05-10T11:52:50.014747"
}
]
}
从响应中可以获取到文档 ID、更新时间等基础信息,但似乎无法获取文档元数据等内容。
通过status字段可以确认文档的导入状态。系统共定义了 12 种状态,包括 “INDEXED(已索引)、IN_PROGRESS(处理中)、IGNORED(已忽略)” 等。状态列表可参考list_knowledge_base_documents方法的官方文档。
statusReason是仅当status为IGNORED时才会设置的字段,通过该字段可了解文档导入被驳回的原因。
4. 确认限制事项
导入不支持的扩展名文档时
支持的 MIME 类型列表记载于ingest_knowledge_base_documents方法的官方文档中。
此处尝试从 AWS 管理控制台导入不支持的 MP3 格式音频文件。

正如预期,文档导入失败。由于从数据源页面无法查看导入失败的原因,因此需要查看日志。
json
{
"event_timestamp": 1745883248556,
"event": {
"document_location": {
"customDocument_location": {
"id": "sample_mp3"
},
"type": "CUSTOM"
},
"request_id": "JweBaHJjtjMEIjA=",
"data_source_id": <数据源ID>,
"status_reasons": [
"Format is not supported for this resource"
],
"knowledge_base_arn": "arn:aws:bedrock:<区域>:<账户ID>:knowledge-base/<知识库ID>",
"status": "RESOURCE_IGNORED"
},
"event_version": "1.0",
"event_type": "IngestKnowledgeBaseDocuments.ResourceStatusChanged",
"level": "WARN"
}
从日志中可确认,导入失败的原因是尝试导入了不支持格式的文档。
导入大容量文档时
根据用户指南,文档的容量限制似乎为 50MB。由于大容量文档难以通过内联方式定义,因此尝试通过 S3 直接导入文档。准备了 60MB 的 PDF 文件作为测试数据。
import uuid
import boto3
bedrock_client = boto3.client("bedrock-agent")
response = bedrock_client.ingest_knowledge_base_documents(
knowledgeBaseId=<知识库ID>,
dataSourceId=<数据源ID>,
documents=[
{
"content": {
"dataSourceType": "CUSTOM",
"custom": {
"customDocumentIdentifier": {
"id": str(uuid.uuid4()),
},
"sourceType": "S3_LOCATION",
"s3Location": {
"uri": "s3://kb-direct-ingest/60mb.pdf",
},
},
},
},
],
)
查看日志后,确认正如预期,因文件大小超过 50MB 而发生错误。
json
{
"event_timestamp": 1745887796152,
"event": {
"document_location": {
"customDocument_location": {
"id": "76191f78-4ddd-4842-ab71-be2a23c1319d"
},
"type": "CUSTOM"
},
"request_id": "JwpIEFnatjMEtNA=",
"data_source_id": <数据源ID>,
"status_reasons": [
"Resource exceeded allowed size limit of 50 Megabytes. Please reduce the resource size and retry"
],
"knowledge_base_arn": "arn:aws:bedrock:<区域>:<账户ID>:knowledge-base/<知识库ID>",
"status": "RESOURCE_IGNORED"
},
"event_version": "1.0",
"event_type": "IngestKnowledgeBaseDocuments.ResourceStatusChanged",
"level": "WARN"
}
此外,JPEG、PNG 等图片格式文件的大小上限似乎为 3.75MB。在导入数据时,需要注意避免超过容量上限。
5. 总结
本次尝试了知识库的自定义数据源与文档直接导入 API 功能。深切感受到这些功能在提升知识库实用性方面的价值,例如实现了多来源信息的知识整合、省去了数据同步流程等。
今后也将持续跟进相关资讯,进一步推进生成式 AI 的应用。